欢迎光临Felix的博客!
茶水自助,点心任选。
📝 最新文章

爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
最近在看布莱恩阿瑟(W.Brian Arthur)的《复杂经济学:经济思想的新框架》时,里面提到的复杂系统的自组织自适应的特点真的很吸引我,其中阿瑟在第二章提出了“爱尔法鲁酒吧问题”,将自适应复杂系统通过一个实验体现了出来,行为主体的每一次决策将影响他们共同存在的环境,而环境又进一步影响行为主...

python字体子集化
中文字体不像英文字体那样,26个大小写字母加一些标点符号就能凑成一套字体文件,轻量小巧。中文中光是常用的汉字就有3500个,所以一套中文字体文件往往会达到3、4mb,多的也有8mb等,如果在web中使用服务器端的中文字体,光是等待加载就要花去不少时间,所以为了使加载速度提升,我们可以采用字体子...

一些用平板画的画和用flipaclip画的动画
前年入手了一个999元的小新pad,加了一支笔,这价格还行,可以做做笔记,偶尔没事在平板上涂涂画画,就挑一些这两三年画得放到博客上,给这个冷清的博客加点烟火气。 ↓ 临摹海绵宝宝里面的船长 <img src="https://img.felixlee.cn/blog/202308...
phpcms通用缓存装饰器,给函数的输出增加缓存
对于一些不会经常变化的数据,或者每次调用需要进行多次sql查询(比如调用一次就需要查十几次数据库)的数据,就可以给这些数据增加缓存,将多次查询合并到一个缓存中,加载速度就会大大加快,而phpcms本身就自带了设置缓存和调用缓存的函数setcache和getcache,我们就基于这两个函数写一个装饰器,给普通的函数非常简单地增加上一个缓存的功能。 缓存装饰器的代码 #缓存装饰器,用于给函数结果增加缓存 function cacheDecorator($func,$cache_key,$expires=3600...

python根据行业根词及百度百科提取行业属性
在构建一些行业或者事物的模型的时候,需要预先设计好相关的字段或属性,举个例子,比如搭建飞机机型的数据库模型时,它可能有的字段有“重量”、“长度”、“机翼长度”、“动力模式”等等,不过在设定这些字段时,一般需要对该行业或者这类事物有一定的了解,所以后面就在构思一种可以通用的、比较快能查询一个行业...

python使用朴素贝叶斯实现简单中文文本分类
之前在看《数据科学入门》——Joel Grus的第13章朴素贝叶斯算法的时候,文章内根据朴素贝叶斯算法实现了一个简单的英文垃圾邮件筛选器,跟着做了一下,还是很好理解的,后面拓展了一下思维,发现运用到中文文本分类上还是很容易实现的,不过是将垃圾邮件区分的二分类问题转换成多分类问题,几分类问题取决...
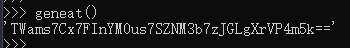
基于时间戳与对称加密实现简单的token验证
之前需要在两台服务器之间频繁传输一些重要数据,一台服务器开放数据接口,另一台调用,为了防止数据泄露,所以简单构思了一下,在接口上添加了一个简单的token验证机制,采用时间戳、base64和密码表来完成,为对称加密。那么下面就带来python的具体实现步骤。 思路一览...

递归打印出树形结构数据(多层级数据)(小思考)
昨天在想如何将树形结构数据,即一层层、有父级子级关系的数据打印出来,而且还能表示层级关系。刚才想了想,感觉用递归比较合适,稍微琢磨了一下发现可行,下面就分享一下这个想法。 先准备一些数据,为了方便演示,我这里就用dict和list的组合来表示数据,另外我们规定每一行的索引即代表该...

活在游戏中的智慧生物,对机器自我意识的展望,成为造物主的梦
之前说了要在博客多发点内容,自然有时间就开搞啦。关于内容题材,我想了想,没必要每次都一定要捣鼓出什么具有“分享”或者“教育”意义的内容,随便聊些生活或者想法还是不错的。 活在游戏中的智慧生物 前段时间跟阿仙去他家附近的影院看了最...
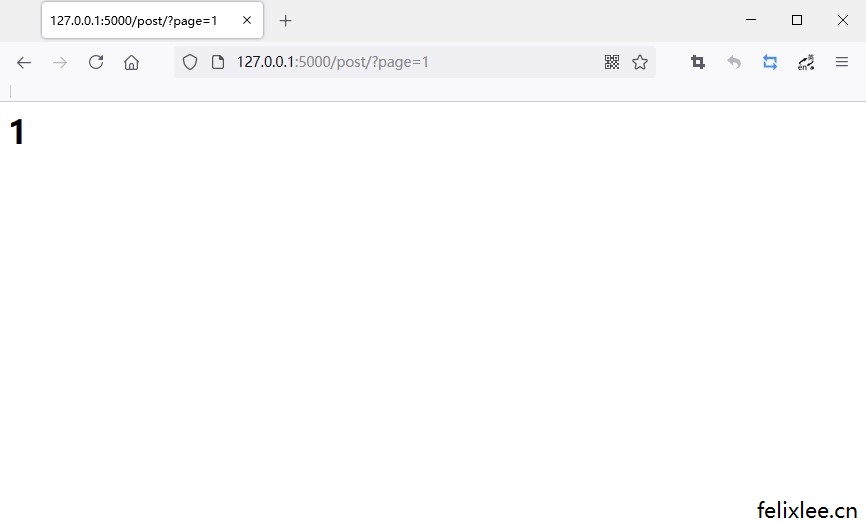
Python Web开发基于flask的博客系统教程(4-1)操作url的参数(查询字符串)
现在我们来到了flask教程的第四章,这一章我们来学习一下如何处理用户向flask传输的数据。 在开始学习之前,我先分享一下http请求中常见的两种方法,分别是GET和POST。 GET和POST方法 <stron...
🤔 我是谁
我是felix,现在在深圳生活。爱好广泛,喜欢尝试新事物。“全职酱油,业余高手”
 粤公网安备 44030702002444号
粤公网安备 44030702002444号