在构建一些行业或者事物的模型的时候,需要预先设计好相关的字段或属性,举个例子,比如搭建飞机机型的数据库模型时,它可能有的字段有“重量”、“长度”、“机翼长度”、“动力模式”等等,不过在设定这些字段时,一般需要对该行业或者这类事物有一定的了解,所以后面就在构思一种可以通用的、比较快能查询一个行业的常见属性的方法,后面发现使用一些百科信息的属性来构建这样一个项目是可行,实施之后也能达到不错的效果,下面就分享一下实现步骤。
思路
1、收集一定数量的该行业/类目的根词,一般15-20个根词获得的属性有较好的通用性
以下为一些示例:
(1)、水果类目:苹果、梨子、西瓜、榴莲、葡萄、香蕉....
(2)、大学类目:清华大学、北京大学、复旦大学、浙江大学、中山大学...
(3)、恐龙类目:霸王龙、翼龙、剑龙、三角龙、异齿龙、迅猛龙...
2、然后根据整理好的行业根词,在百度百科中都查询一遍,并收集整理每个百科页面的属性,这里仅保存属性名,不保存属性值,输出一个属性名的list。

3、将所有的属性名合并到一个list当中,然后按照出现次数从大到小排序,这样就可以得到一个比较普遍的属性列表了。
操作
1、获取单个根词的属性
编写一个百度百科的爬虫函数,传入参数为关键词,输出该百科的属性名列表,可以多加一个参数用于限制结果,因为有些百度是重名但是意思不同的。
import requests
from lxml import etree
def getBaikeAttrs(keyword,limit=[]):
#...
return attr_list
输出结果类似下方

2、合并一系列根词的属性,并按照出现次数排序
编写一个查询一系列根词的函数,然后将获取的所有属性合并,接着使用python的内置函数Counter计算各类属性的出现次数,然后根据出现次数排序,接着将属性与出现频率组合为一个dict返回。
#获取一系列根词的属性
def getTypeAttrs(keywords,limit=[]):
all_attrs=[]
for keyword in keywords:
try:
attrs=getBaikeAttrs(keyword,limit)
all_attrs+=attrs
except:
pass
return all_attrs
#按照出现频次排序返回
def sortTypeAttrs(keywords,limit=[]):
all_attrs=getTypeAttrs(keywords,limit)
all_attrs_count=Counter(all_attrs)
all_attrs_sorted=sorted(all_attrs_count.items(),key=lambda x:x[1],reverse=True)
all_attrs
return all_attrs_sorted
输出的效果类似下方,这样我们就可以挑选一些频次较高的类目作为模型的字段/属性了
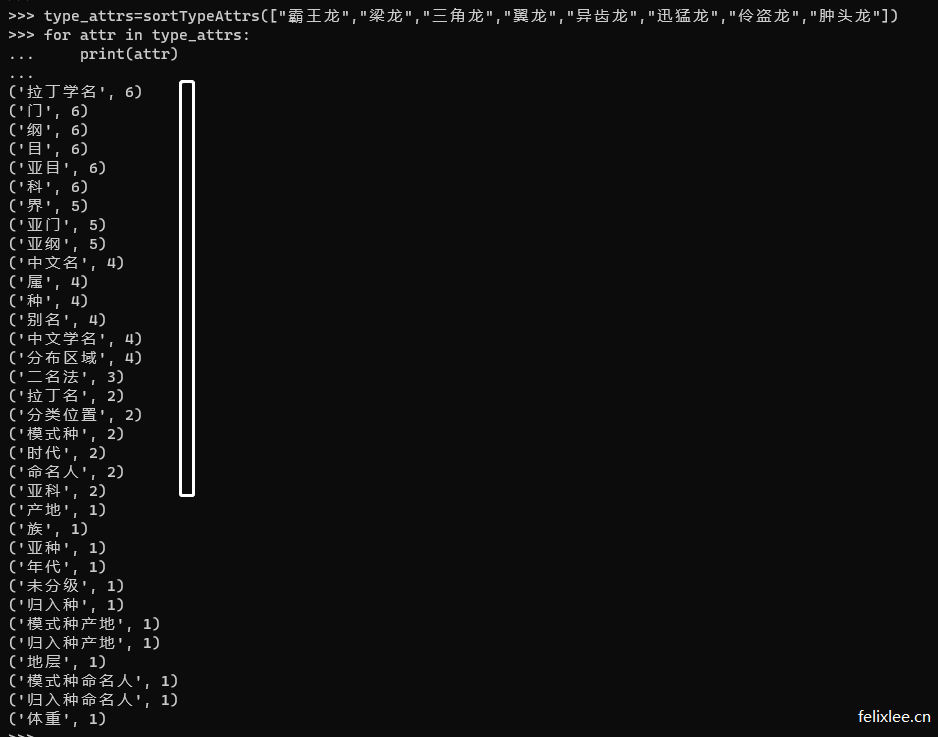
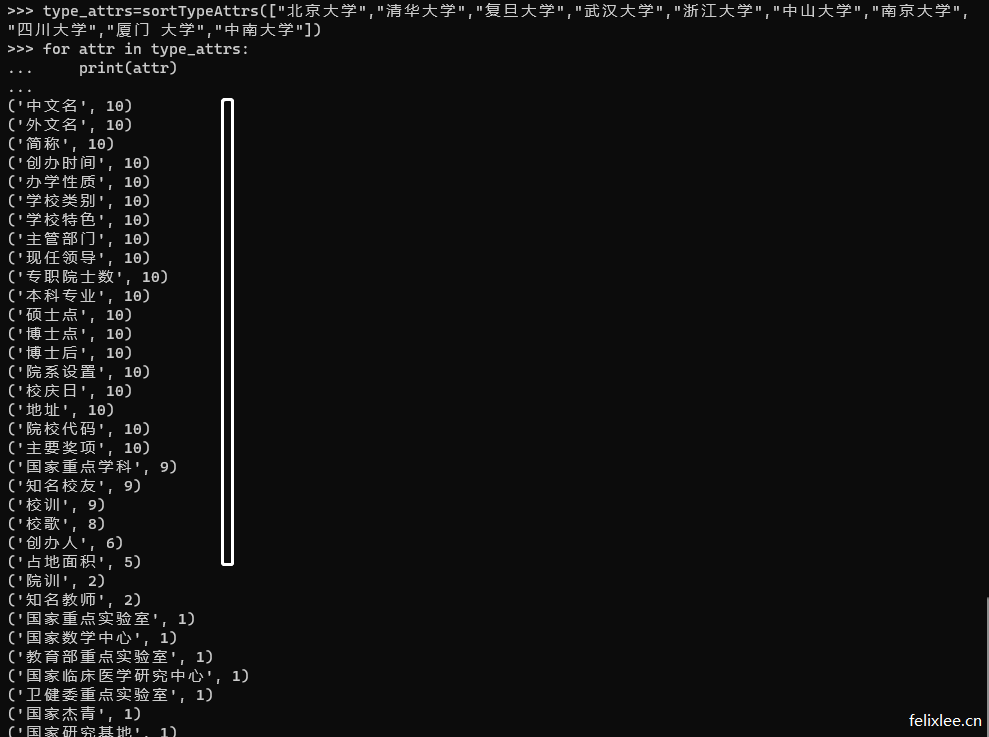
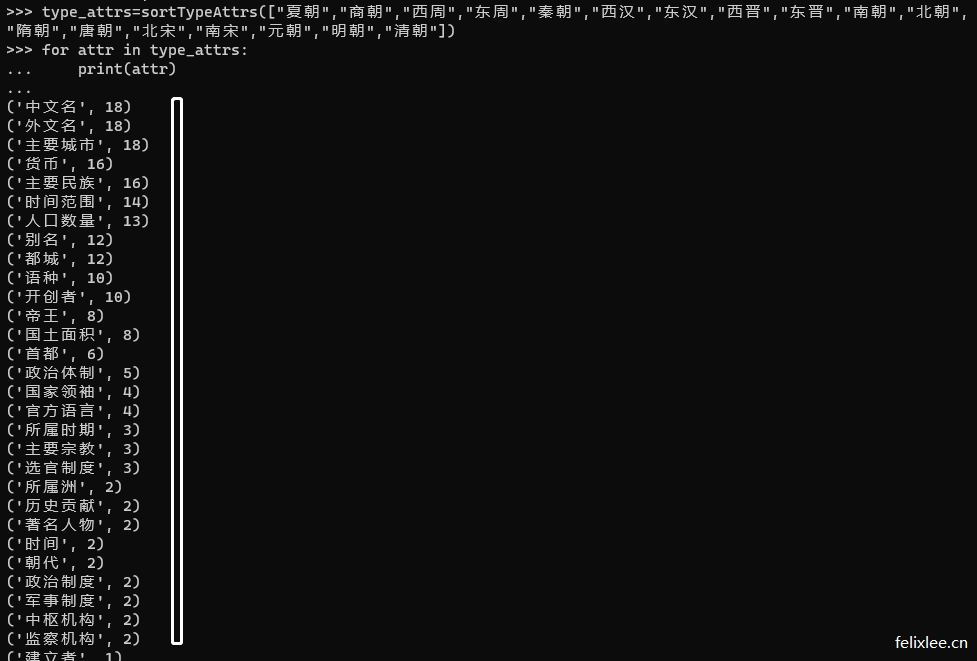
常见事物属性整理
下面整理一些常见事物的属性
恐龙类目属性
| 属性 | 属性 | 属性 | 属性 |
|---|---|---|---|
| 拉丁学名 | 门 | 纲 | 目 |
| 亚目 | 科 | 界 | 亚门 |
| 亚纲 | 中文名 | 属 | 种 |
| 别名 | 中文学名 | 分布区域 | 二名法 |
| 拉丁名 | 分类位置 | 模式种 | 时代 |
| 命名人 | 亚科 | - | - |
大学类目属性
| 属性 | 属性 | 属性 | 属性 |
|---|---|---|---|
| 中文名 | 外文名 | 简称 | 创办时间 |
| 办学性质 | 学校类别 | 学校特色 | 主管部门 |
| 现任领导 | 专职院士数 | 本科专业 | 硕士点 |
| 博士点 | 博士后 | 院系设置 | 校庆日 |
| 地址 | 院校代码 | 主要奖项 | 国家重点学科 |
| 知名校友 | 校训 | 校歌 | 创办人 |
| 占地面积 | - | - | - |
中国朝代属性
| 属性 | 属性 | 属性 | 属性 |
|---|---|---|---|
| 中文名 | 外文名 | 主要城市 | 货币 |
| 主要民族 | 时间范围 | 人口数量 | 别名 |
| 都城 | 语种 | 开创者 | 帝王 |
| 国土面积 | 首都 | 政治体制 | 国家领袖 |
| 官方语言 | 所属时期 | 主要宗教 | 选官制度 |
| 所属洲 | 历史贡献 | 著名人物 | 时间 |
| 朝代 | 政治制度 | 军事制度 | 中枢机构 |
| 监察机构 | - | - | - |
其他
了解事物属性、行业属性对于构建行业模型、挖掘行业需求都有一定的作用。比如需要构建一个行业网站,那么使用常见的属性作为模型字段,在后续的功能设计上都能产生作用,最简单的就是可以用于字段筛选,也是最直观的作用。
-
最新文章
- 爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
- python字体子集化
- 一些用平板画的画和用flipaclip画的动画
- phpcms通用缓存装饰器,给函数的输出增加缓存
- python根据行业根词及百度百科提取行业属性
- python使用朴素贝叶斯实现简单中文文本分类
- 基于时间戳与对称加密实现简单的token验证
- 递归打印出树形结构数据(多层级数据)(小思考)
-
最新随笔
- 海洋公园逛逛(ps:北极熊馆动物状态都感觉不太好)
- 半夜梦到一段诗,但醒来不太记得全部,让deepseek续写一下,我只记得前面是: “当元论状赵金海,不出凭栏***” 至于为什么会突然起来记下这段诗,是空调水一直滴在琴上,给我吵醒了(惊醒!),深圳台风刚过,湿度大
- 渐变
- 周末打开摩尔庄园给拉姆喂点吃的,碰到个大佬带着同服的一群人去一大堆以前的老场景逛嘞。对我来说,印象最深刻的是浆果丛林刚开放的那段时间。
- 稍微调整一下首页样式(旧 → 新)
- 给随笔页面加了个动态加载的功能,不然一次性加载太多图片访问有点慢
- 这个桥去年来看的时候貌似还没有
- 中秋经典BGM:滴滴滴
 粤公网安备 44030702002444号
粤公网安备 44030702002444号